
Tradmark Good-Services Text Classification by NLP CNN deep-learning model
Menu
- Tradmark Good-Services Text Classification by NLP CNN deep-learning model
Trademarks can be words, images, sounds, colors, or combinations thereof. One important thing for a tradmark is its class number and good-services description. There are 45 classes based on the Nice Classification (NCL), an international classification of goods and services used for trademark registration.
One of the key steps in examining a trademark application is determining the international class of the applied trademark based on the description of goods and services. I think it’s a good idea to do this with a deep learning model. There are many methods or models that can do this, such as CNN, LSTM, RCNN, BERT. First, train a CNN model to see the effect.
Data Source
There are official IP office data from many countries which could be as the data source. Based on the convenience of acquiring data, here I use US IPO data as the example (unlike some countries, USPTO provides the public data)
(the data could be downloaded from USPTO bulkdata)
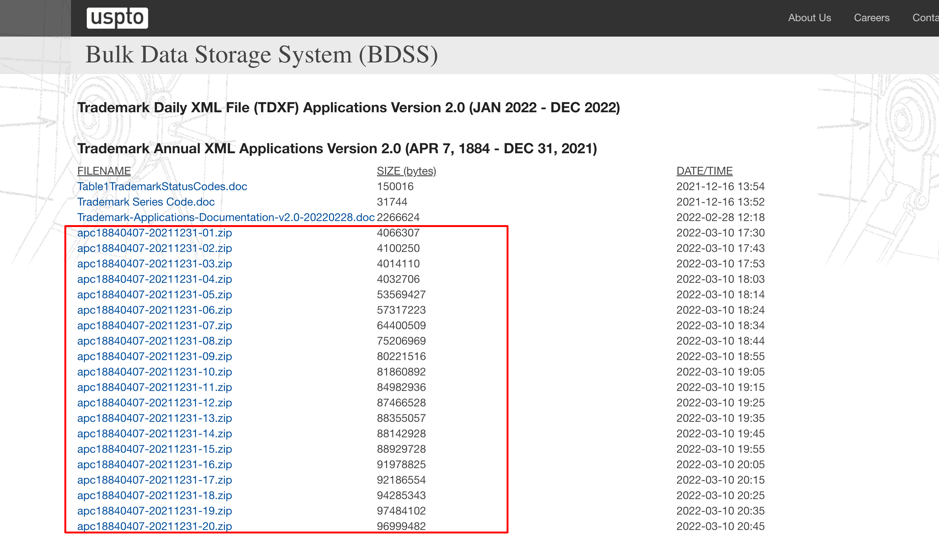
there are two parts of data:
- base data which includes data from the 19 century to a specific time(currently it’s the end of the year 2021)
- incremental data which would be generated daily
the base data is quite enough for us to train this CNN classification model. After downloading them all by using a simple script, we could enter the data cleaning stage.
Data Preparation
Data Extraction
firstly, we need to extract the class number and good-service text from the data source. Before we start the script, let’s look at the specification document named “Trademark-Applications-Documentation-v2.0-20220228.doc” which could also be downloaded from USPTO:

Then we knew the class number and good-service text are under the tag <case-file-statements>.
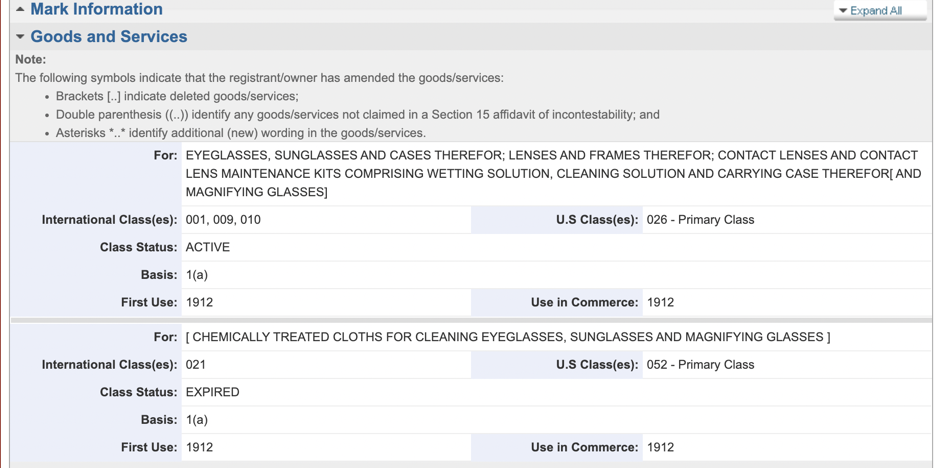
The following example is from the snippet for application number 72360420:
<case-file>
<serial-number>72360420</serial-number>
……
<case-file-statements>
<case-file-statement>
<type-code>D00000</type-code>
<text>NO CLAIM IS MADE TO THE WORD "OPTICAL" APART FROM THE MARK AS A WHOLE.</text>
</case-file-statement>
<case-file-statement>
<type-code>GS0261</type-code>
<text>EYEGLASSES, SUNGLASSES AND CASES THEREFOR; LENSES AND FRAMES THEREFOR; CONTACT LENSES AND CONTACT LENS MAINTENANCE KITS COMPRISING WETTING SOLUTION, CLEANING SOLUTION AND CARRYING CASE THEREFOR[ AND MAGNIFYING GLASSES]</text>
</case-file-statement>
<case-file-statement>
<type-code>GS0521</type-code>
<text>[ CHEMICALLY TREATED CLOTHS FOR CLEANING EYEGLASSES, SUNGLASSES AND MAGNIFYING GLASSES ]</text>
</case-file-statement>
</case-file-statements>
There are 2 good services as described in the code GS0261 and GS052, however, those class 26 and class 52 are PRIOR U.S. CLASSES OF GS, instead of NICE Classification. I didn’t find the NICE class number for that application in the XML. As the layman in IP trademark, I guess that USTPO stored the NICE class number in the XML after a certain year. Hence when we use Pyspark to fetch the class number and gs from the source data, I decide to process the data after 1990 only, to avoid the US class number mixed in.
then we could use Pyspark to kick off the data preparation stage:
import findspark
findspark.init()
from pyspark import SparkContext
sc = SparkContext("local", "uspto_pyspark")
input_file = "XXXXX.xml"
from pyspark.sql import SparkSession
from pyspark.sql import functions as f
spark = SparkSession.builder.config("spark.sql.warehouse.dir").appName("uspto_preprocess").getOrCreate()
df_ori = spark.read.format("com.databricks.spark.xml").option("rowTag","case-file").load(input_file)
df_ori.select(
"*",
f.explode("case-file-statements.case-file-statement")
).filter(
f.substring(f.col('col.type-code'), 0, 2) == 'GS'
).select(
f.col("serial-number").alias("application_number"),
"case-file-header.filing-date",
f.column("col.text").alias("gs"),
f.substring(f.col("col.type-code"), 4, 2).alias("cls")
).filter(
f.col("filing-date")>="19900101"
).select(
"application_number","cls","gs"
).show()
the following is the output for samples:
+------------------+---+--------------------+
|application_number|cls| gs|
+------------------+---+--------------------+
| 75916583| 35|Managing hotels a...|
| 75916583| 43|RENTING OF TEMPOR...|
| 76483458| 05|Human vaccine pre...|
| 77659455| 43|Hotel, bar and re...|
| 77659460| 43|Hotel, bar and re...|
| 77911652| 43|Hotel, bar and re...|
| 86081025| 43|hotel, bar and re...|
| 86299351| 09|Protective cases ...|
| 86310386| 37|Management of rea...|
| 86310386| 36|Real estate servi...|
| 86310386| 35|Market research, ...|
| 86745892| 43|hotels, hotel res...|
| 87112551| 44|Farming services ...|
| 87601142| 05|Dietary and nutri...|
| 87601142| 35|Retail services p...|
| 87626338| 43|HOTEL, BAR AND RE...|
| 88015783| 43|HOTEL, BAR AND RE...|
| 90021244| 43|hotel, bar and re...|
| 90172577| 25|jackets, pants, s...|
| 90659148| 41|Entertainment ser...|
+------------------+---+--------------------+
only showing top 20 rows
after we output them from Pyspark to a CSV file, which could be as a staging file, we could go to the next stage: data cleaning
Data Cleaning
Loading Data
df_ori = pd.read_csv(ORI_CSV_INPUT_FILE)
df_ori.gs = df_ori.gs.str.split(";")
df_ori = df_ori.explode("gs")
df_dedup = df_ori[df_ori.duplicated(subset=['cls','gs']) == False]
Normalization
lower the chacraters and remove the special char
df_dedup.gs = df_dedup.gs.str.lower()
df_dedup.gs = df_dedup.gs.str.replace(r"[^a-zA-Z0-9 ]", "", regex=True)
Step Word Removing
from nltk.corpus import stopwords
regex_stop_words = [rf"\b{item}\b" for item in stopwords.words("english")]
regex_stop_words = "|".join(regex_stop_words)
df_dedup.gs = df_dedup.gs.str.replace(rf"{regex_stop_words}", "", regex=True)
Stemming and Lemmatization
skip it due to the usage of word2vec in this model
de-duplicate finally again begore export the data
df_dedup = df_dedup[df_dedup.duplicated(subset=['cls','gs']) == False]
simple check
pd.set_option('display.float_format', lambda x: '%.0f' % x)
df_dedup[["cls"]].describe()
there are 940,472 good-service texts that could be used in model training, and we could see there is no US class number (such as class 52 and etc)
| count | 940472 |
| mean | 22 |
| std | 14 |
| min | 0 |
| 25% | 9 |
| 50% | 21 |
| 75% | 36 |
| max | 45 |
Data tokenization
from keras.preprocessing.text import Tokenizer
from copy import deepcopy
import json
all_sentence_gs = df['gs'].values
tokenizer = Tokenizer(num_words=None, oov_token=OOV_TOKEN)
old_word_index = deepcopy(tokenizer.word_index)
tokenizer.fit_on_texts(all_sentence_gs)
for item in tokenizer.word_index.keys():
if item not in old_word_index.keys():
old_word_index[item] = len(old_word_index)+1
tokenizer.word_index = old_word_index
word_index = old_word_index
# fetch counts for all words except oov_token
words_count = json.loads(tokenizer.get_config()['word_counts'])
Build Embedding Matrix
As for the embedding matrix, I decide to train based on the pre-trained word2vec matrix, the pre-trained one used in this case is from http://vectors.nlpl.eu/repository/#
Corpus: English Wikipedia Dump of February 2017 and Vector size=300
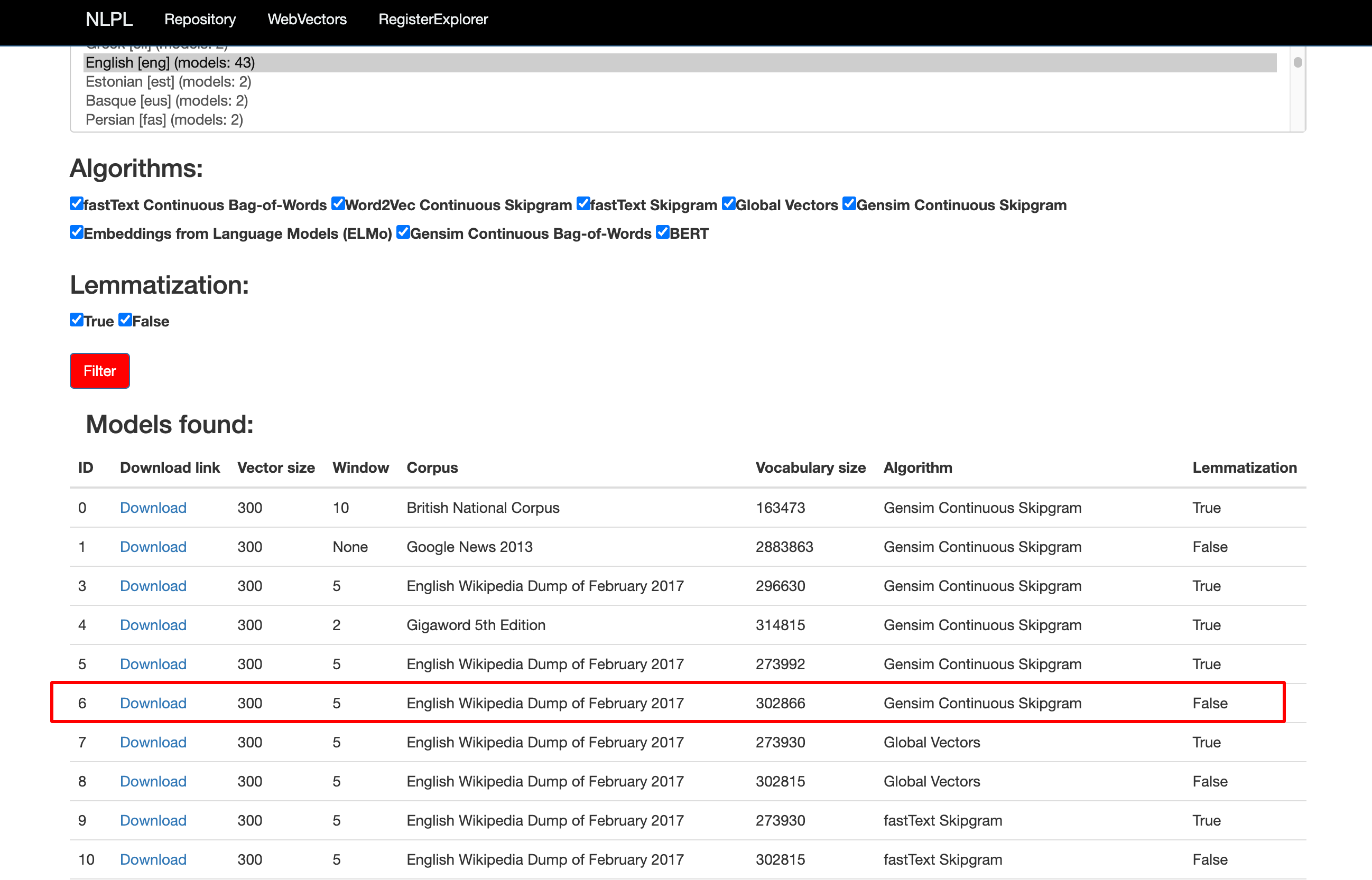
the following code could build our own based on the tokenized data in the previous step, and also record those words which didn’t exist in the pre-trained word2vec matrix
import numpy as np
vocab_size = len(word_index) + 1 # Adding again 1 because of reserved 0 index
embedding_matrix = np.zeros((vocab_size, EMBEDDING_DIM))
with open(WORD2VEC_ORI_FILE, "rb") as fr:
word2vec_matrix = pickle.load(fr)
no_exist_words = {}
for word in word_index.keys():
idx = word_index[word]
try:
embedding_matrix[idx] = word2vec_matrix[word]
except Exception:
if word == OOV_TOKEN:
continue
no_exist_words[word] = words_count[word]
words didn’t exist in the word2vec matrix
the output from below code could reveal something before we train the model
import pandas as pd
df_no_exist_words = pd.DataFrame.from_dict(no_exist_words,orient='index',columns=['c'])
print(f"df_no_exist_words.shape = {df_no_exist_words.shape}")
print(f"df_no_exist_words.describe: {df_no_exist_words.describe()}")
print(f"95% quantile at df_no_exist_words: {df_no_exist_words.quantile(0.95)}")
print(f"5% of df_no_exist_words = {df_no_exist_words.shape[0] * 0.05}")
outout:
df_no_exist_words.shape = (30968, 2)
df_no_exist_words.describe: c
count 30968.000000
mean 6.371351
std 47.744301
min 1.000000
25% 1.000000
50% 1.000000
75% 3.000000
max 3568.000000
95% quantile at df_no_exist_words: c 18.0
Name: 0.95, dtype: float64
5% of df_no_exist_words = 1548.4
the above stat is based on the count of no-exist words that appear in the whole dataset, let’s list the top 10 no-exist words based on that:
term|count
-
e 3568 dvds 3314 roms 2918 dvd 2459 pullovers 2237 distributorships 1943 x 1348 rainwear 1140 cardigans 1072
I actually don’t worry too much about them, because if some words not existed in the pre-trained word2vec matrix but it’s important and repeats (appear) many times in the training data, I think the deep learning model could train and give the proper weight to them.
from the above output, we could see there are 95% of no-exist words(30,968 * 95%) appear in the whole dataset less than 18 times, which I think we could ignore(though the model would train and I don’t think those non-important words which appear rarely would gain some weight)
CNN Model Training
Model Structure
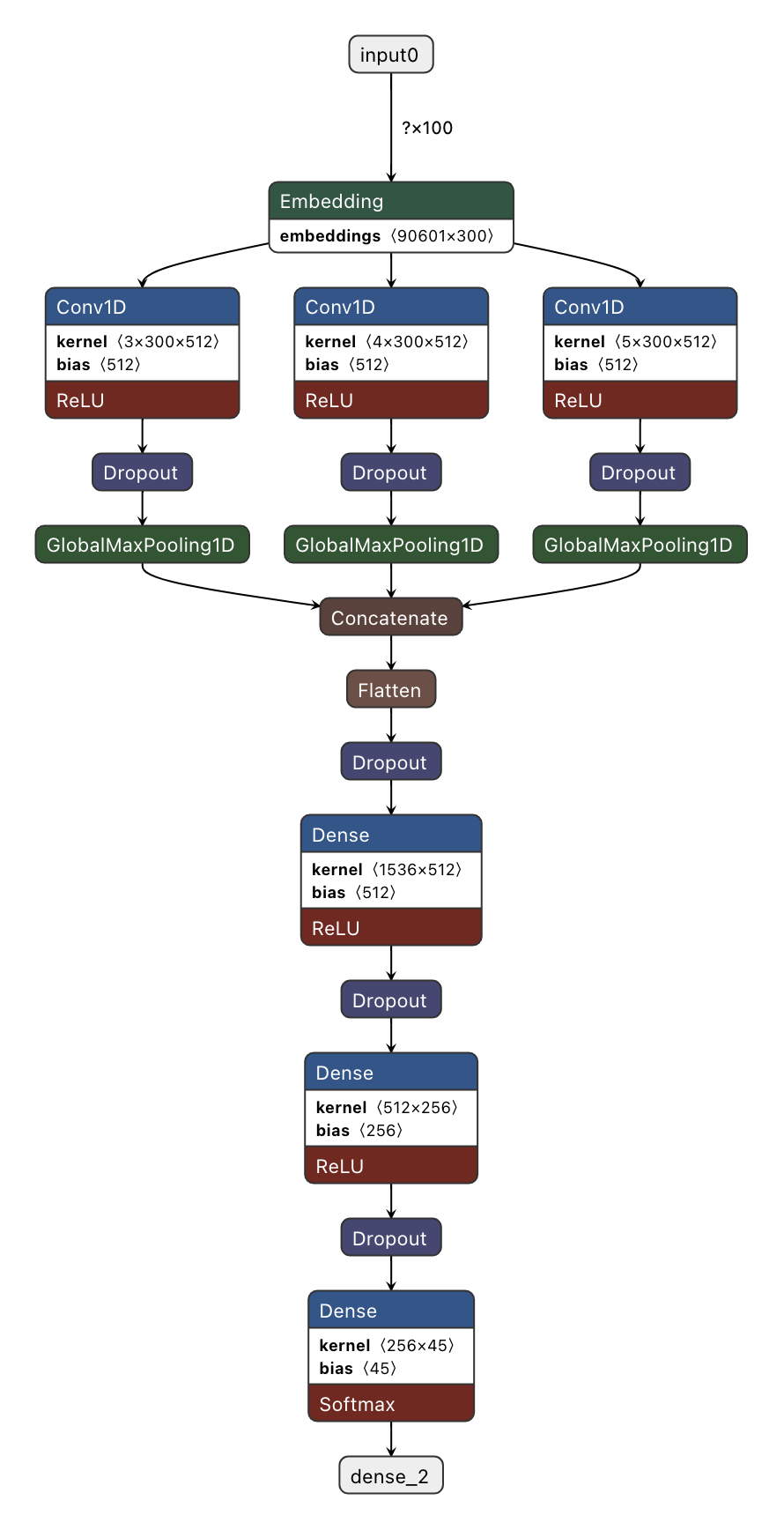
Based on the classic CNN model structure(refer to the below for model diagram), I create my own CNN model.
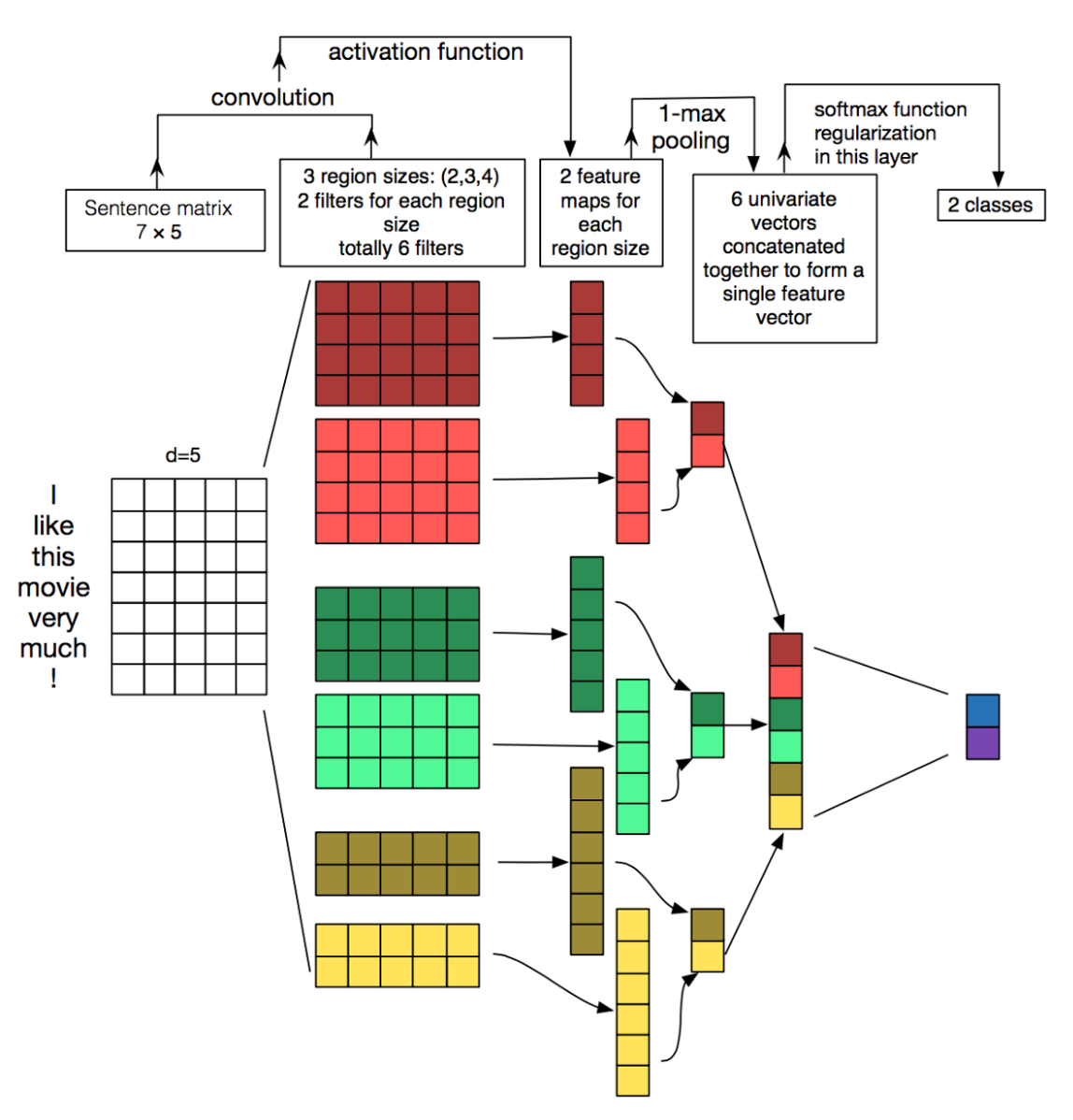
of course, my first model is crap and does gain a not high enough accuracy. Hyper-parameter tunning is painful work for me, after lots of tries and adjustments on the model, the last model is like the below:
Details on the process
firstly, I got the over-fitting not surprisingly as shown in the below picture:
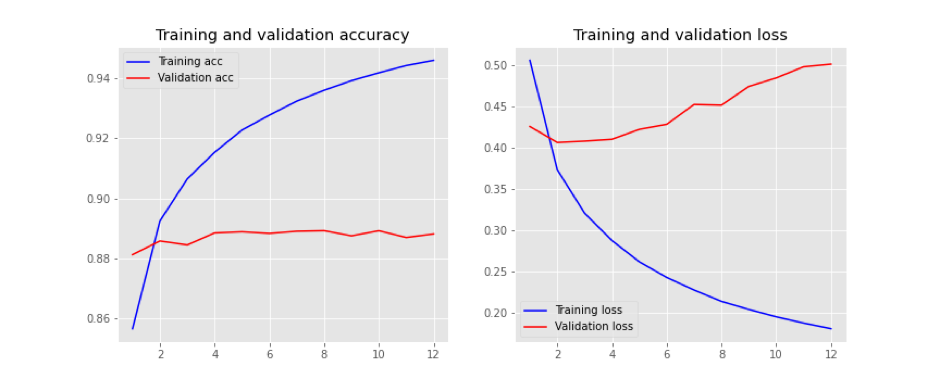
from the 2nd epoch, the loss of the validation set is increasing and the accuracy is not convergent.
after I added the extra Dropout layer with 50% dropping and also used L2-Regularization, I got this:
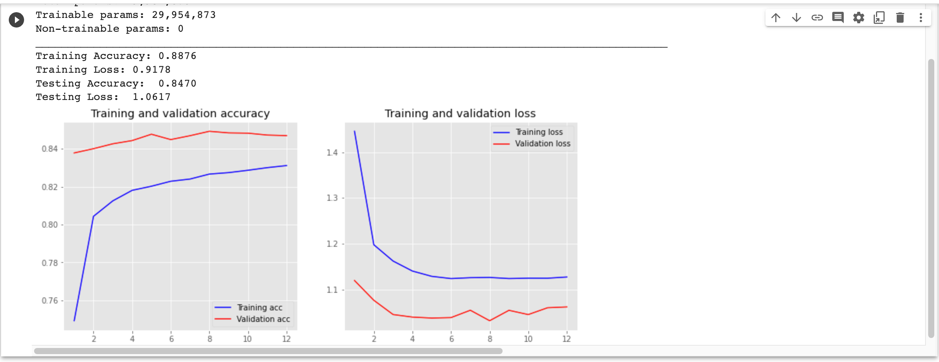
this time, the loss of the train set and validation set didn’t go far away with each other, but the weird thing is the accuracy of validation is higher than that of training. then I increase the batch_size from 64 to 256 and also train the model with 80% data. then I got a not-bad picture:
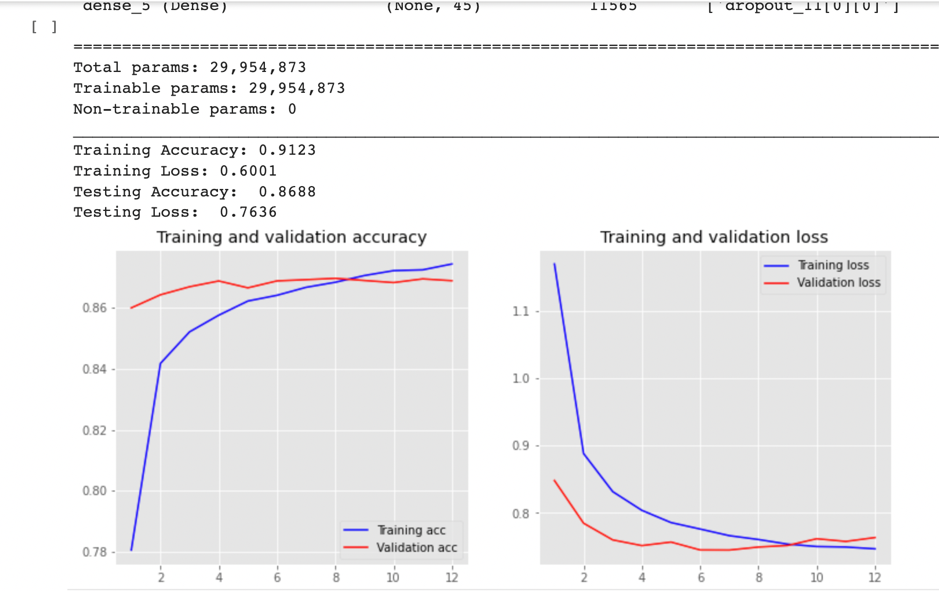
the accuracy on the test set is 86.88%, then I continue to increase the batch_size t0 512 and train it with full data (940,472 records), at last, I got 87.72% accuracy
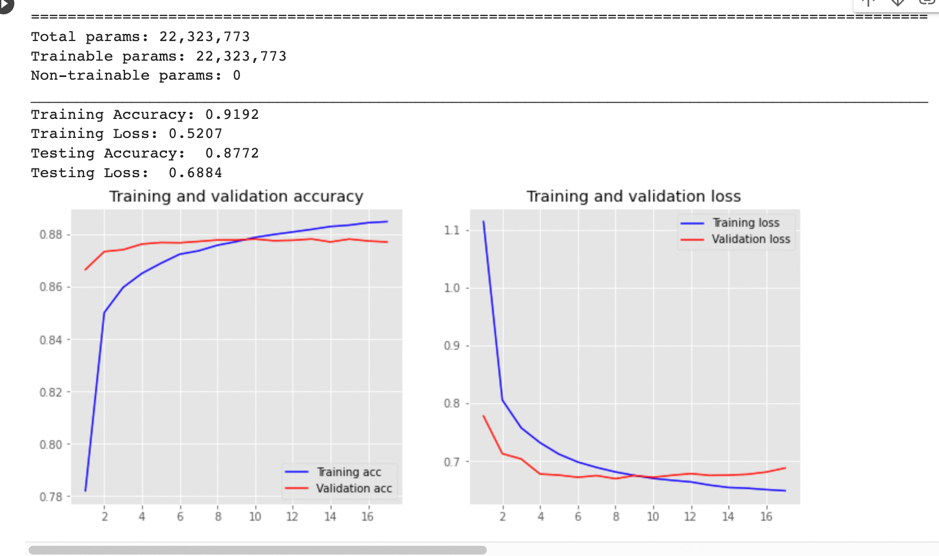
Things to be improved
roughly, the result from a trained CNN model is not too bad. However, there are some points to be improved:
- to check the weight of embedded matrix trained in the model, the 0 weight value of words might bring some idea.
- the max lenght of the gs is 1410, to check the distribution of gs length to decide if there is necessary to train a seperate model for long content gs
- to validate test data set and statistics on class number could help to see if the model works badly on some specific class
- CNN could be the baseline for this experiment, other model such as RNN,LSTM, BERT could be implemented for this task.
